Why now? The primary system employed by storage providers in the modern era is to use HTTP and HTTPS GET and POST requests to pull and place records in servers. While this system has functioned relatively well until now, it has a number of dangerous vulnerabilities derived from its centralized structure.
IPFS proposes a decentralized, peer-to-peer alternative, where network participants share bits and bytes with eachother directly, without the need for a centralized intermediary. This can not only increase security, but also make the network more efficient.
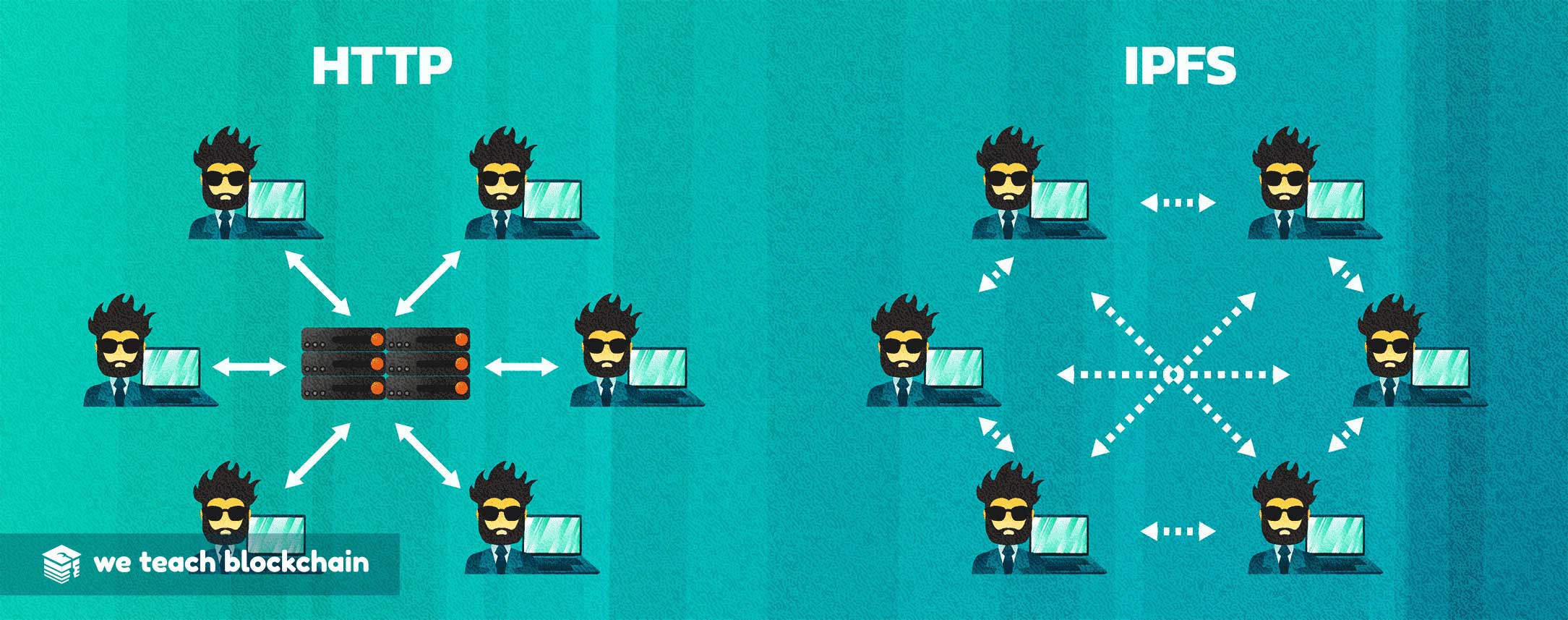
In particular, when HTTP calls are routed, they use the central domain service to request files by their relation to a particular URL. As a result, all files on the network must belong to a particular domain and must be hosted on a particular connected device.
In contrast to centralized architecture, IPFS uses purely peer to peer transfer of data. Each file is hosted across a network of connected nodes which each participate independently of each other. Because there’s no central owner, it’s very hard to censor this network or prohibit access to a file. Additionally, because files are spread across all of the nodes, so no single node will ever have control of or access to all copies of a particular file.
In the next section, we’ll get you started using the IPFS browser to explore the network.




